

Abstract
A cryptographic vulnerability in the development software Telerik UI that was discovered in 2017 has long been considered impractical to exploit. Until now. Research by Security Research Labs (SRLabs) shows that this impracticability was only due to the unoptimized nature of the publicly available exploit. Optimization strategies unveiled a practical exploit for remote code execution within infrastructure. Learn how the 2017 Telerik vulnerability was successfully exploited in a large corporation in 2021, the optimization techniques deployed, which can also be applied to similar cryptographic issues in other software, and how to protect your infrastructure.
This post provides an understanding of the vulnerability and the original exploit. With that in mind, a new, optimized version of the exploit is developed. Finally, the key takeaways in relation to exploit optimization are summed up.
Introduction
During a Red Team engagement, a Fortune500 company’s subsidiary had a promising vulnerability: a cryptographic weakness in Telerik UI (CVE-2017-9248). However, the publicly available exploit was inefficient, hindering timely and undetectable access.
Different optimization strategies enabled the team to increase the exploit’s speed by approximately 100 times for the average case.
The exploit’s speed increased by around 250 times, resulting in 78k/314 and 39k for the worst-case scenario.
It allowed the Red Team to gain a foothold and eventually move on to the headquarters.
Hacking applications using Progress Telerik products
Progress Telerik develops user interface (UI) controls and components for .NET and JavaScript frameworks, to build engaging apps. Over 275,000 customers, including Visa, Microsoft, and Samsung, utilize Telerik products. However, only one product, Telerik UI for ASP.NET AJAX, is affected by this particular vulnerability.
The risk arising from CVE-2017-9248
In 2017, researchers identified a cryptographic vulnerability in one component of the Telerik product. The DialogHandler component invokes file browsers (Web UI Dialog Windows) and receives plaintext and encrypted parameters via a URL. Two of these encrypted parameters play a crucial role in determining whether file uploads are allowed and specifying the permitted file extensions. If a hacker can guess or gain access to the secret, they can invoke a file browser and upload files, potentially compromising vulnerable websites by uploading .aspx web shells. Despite researchers discovering this vulnerability in 2017, it remains prevalent in the wild, even in recent engagements.
Slow and easily detectable public exploit
The team quickly found the exploit, that in theory would allow them to access the the companies infrastructure. Nevertheless, the team decided to abandon the execution of the exploit upon realizing that it was excessively slow in breaking the key and generated a significant amount of noise. Limited key character set and disregarding time constraints in simulations may yield different outcomes.
In order to create a practical exploit, the team dove deeper into the vulnerability trying to optimize it.
Deep dive into CVE-2017-9248
DialogHandler.aspx component attracts hacker attention with file upload and extension capabilities when invoking windows. The request specifies these parameters in the “dp” argument, and they undergo multiple conversions until the plaintext arguments are derived (refer to Figure 1). The exploit aims to determine the secret key stored on the server, which it then employs in an XOR operation to decrypt the parameters.
Sending different parameters to the server result in different error messages (note: error messages shown in the blog are abbreviations). These error messages can be used to guess the secret key.
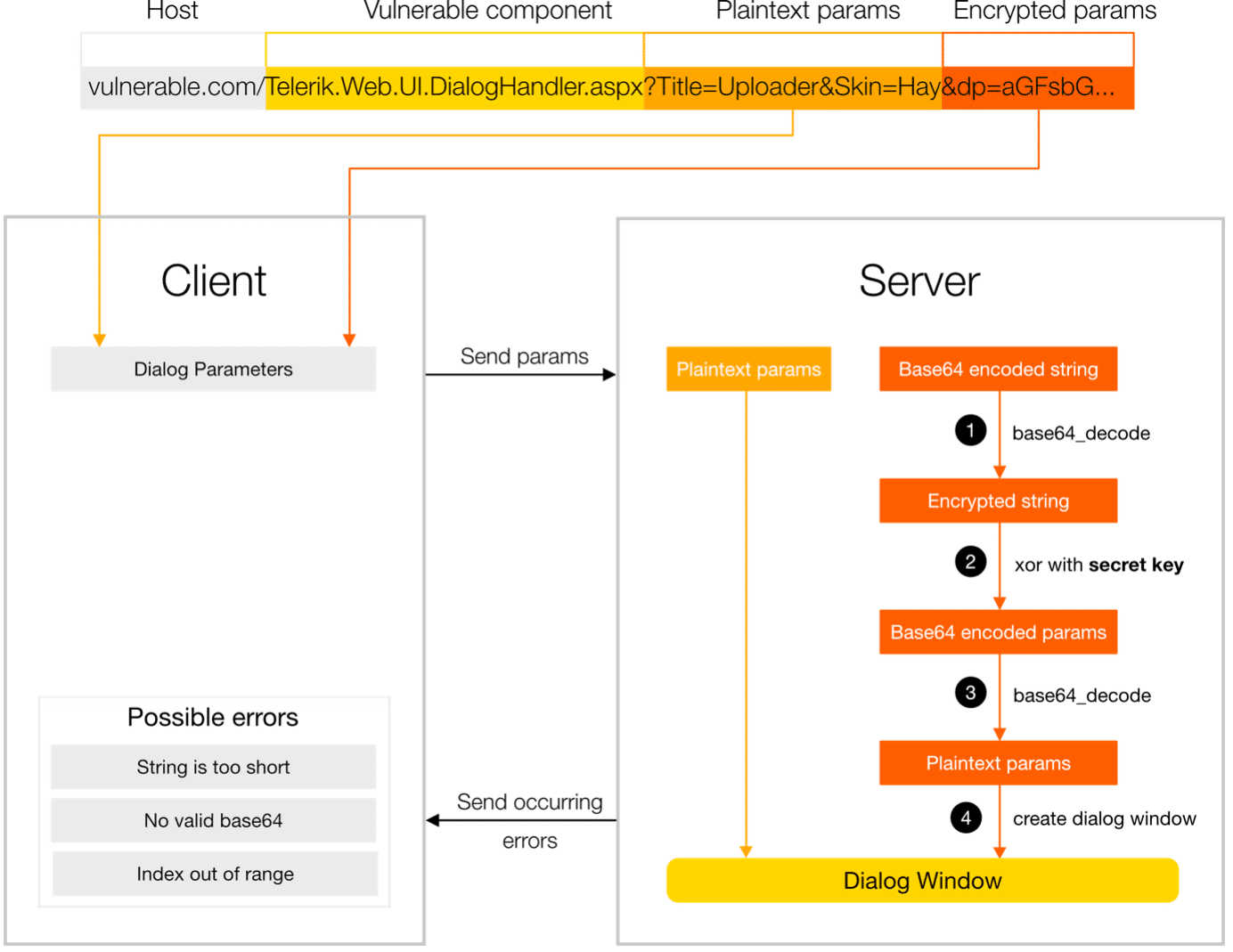
Table 1 displays the three potential error messages used for guessing the secret key and identifies their respective locations in the server-side chain of operations.The positive error message, referred to as the “Index out of range” error message, occurs during step 4 and signifies that the guessed key is a potential candidate (without confirming its correctness). “No valid base64” indicates that it is wrong. There is no need to include “String is too short” here for the sake of completeness since the server always receives base64-encoded strings, ensuring they are always a multiple of 4.

Figure 2 displays encoded strings sent to the server and their corresponding error messages. Request 7’s error message reveals successful decoding, XOR-ing, and valid base64 generation.
Note: This occurrence may be accidental and does not confirm the accuracy of our guessed key.
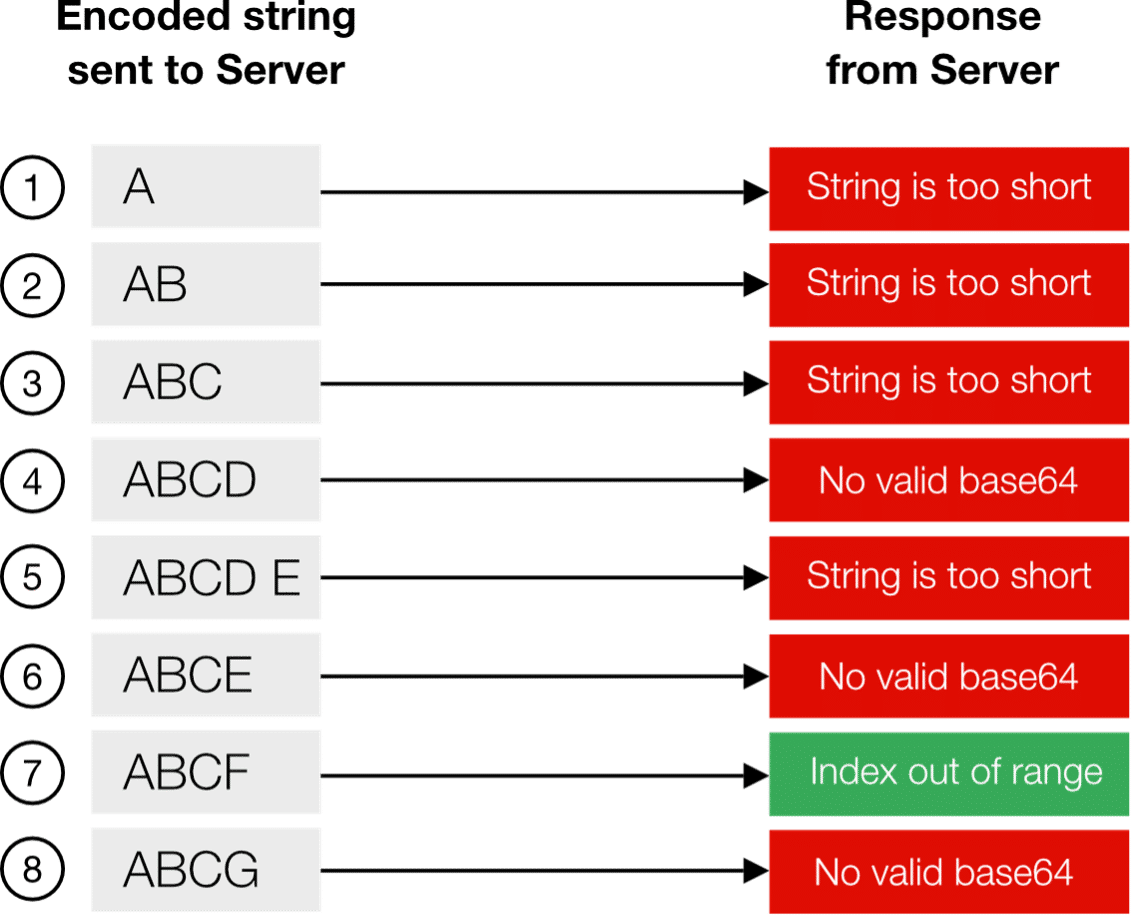
Figure 2: Different encrypted strings and corresponding error messages
Figure 3 gives more detail of the chain of operations on the server-side. It visualizes the exchange between sending the encrypted string to the server and receiving the response from it.
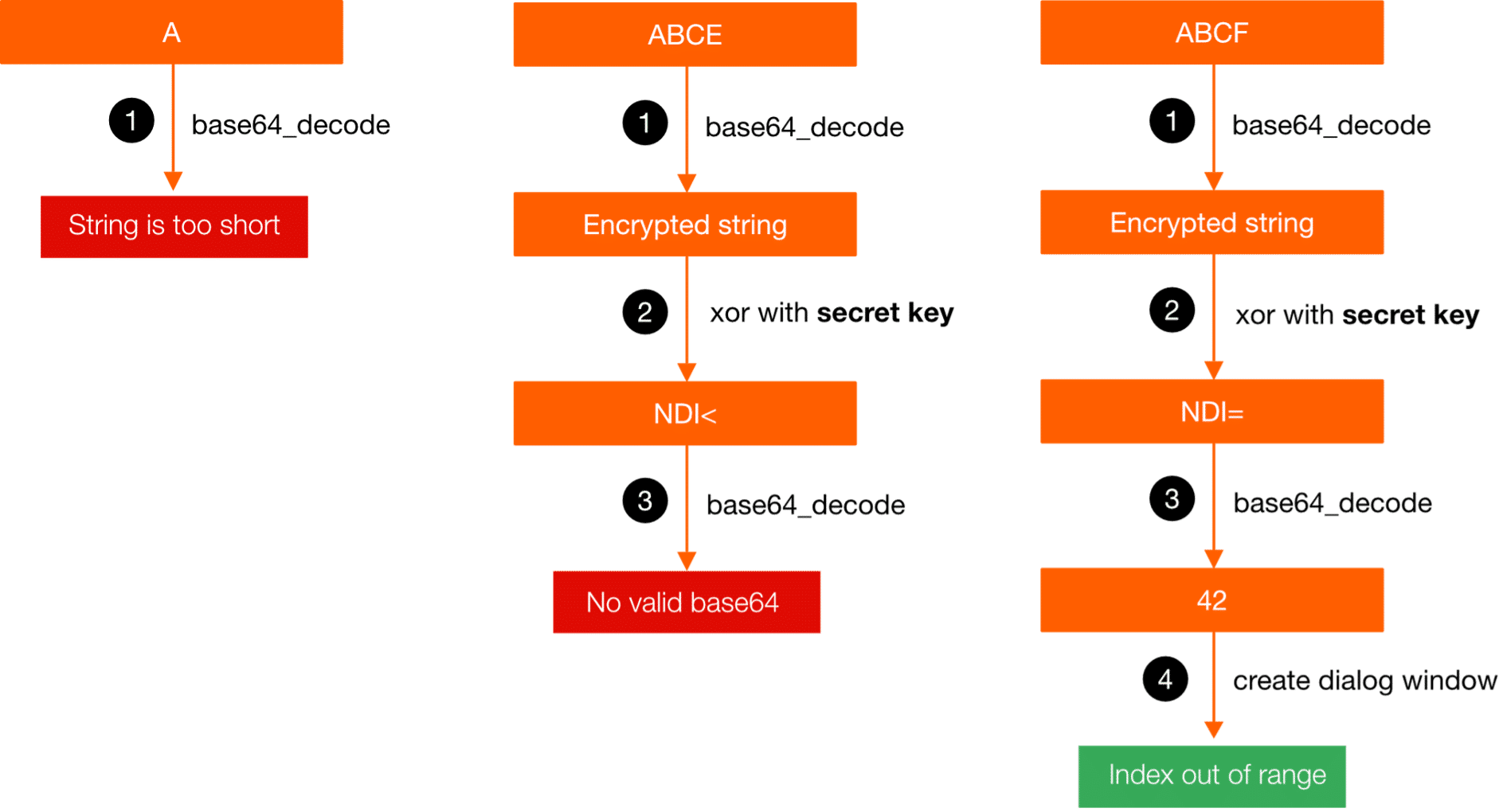
Underlying assumptions for exploits
Before addressing the exploits, two underlying assumptions need to be clarified to ensure comparability between the exploits:
- The team assumed that the secret key could consist of all 95 printable ASCII characters.
- If no key is set by the user in the web.config, there are several fallback methods, which automatically generate a key with a length of 48. The team therefore assumed that the secret key has a default length of 48 characters.
-
To exploit the vulnerability, it is necessary to have the precise version of Telerik UI (e.g., 2017.3.913) and encrypt it along with the other parameters. For the sake of simplicity, the original study omitted this specific detail.
The researches analyzed 3 ways to exploit the vulnerability:
- Exploit 0: Trivial un-optimized Brute-Forcing
- Exploit 1: An Optimized First Workable Exploit
- Exploit 2: A Fully Optimized Exploit
Exploit 0: Trivial Brute-Forcing
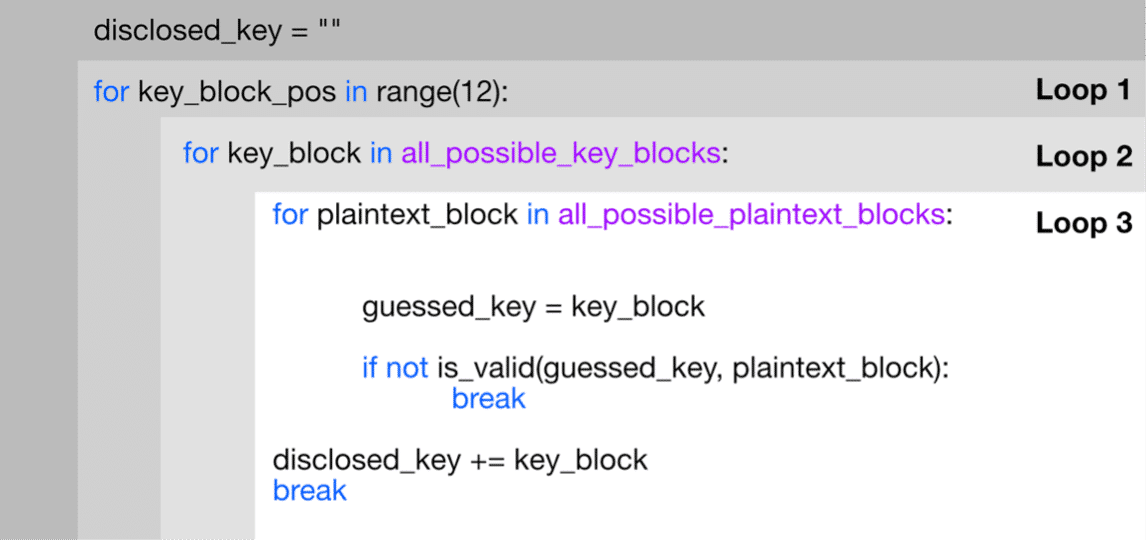
The most trivial approach to brute-forcing the secret key consists of three nested loops:
- Loop 1 loops over each of the 12 secret key blocks, consisting of 4 characters each (12).
- Loop 2 loops over each key character combination for each of these secret key blocks (95^4).
- Loop 3 loops over all possible combinations for the plaintext (64^4) and encrypts each of these combinations with the key character combinations from loop 2.
Testing all possible combinations of the plaintext and obtaining a consistent positive error message from a secret key block indicates the discovery of the correct secret key block. This approach can take extremely long as it does not make use of available information. E.g., the approach has no way to find out which key character caused the decryption to fail in the first place. Therefore, it could require up to 12 * 95^4 * 64^4 requests, which is astronomically high.
Exploit 1: A First Workable Exploit
The method SRLabs tried out at the very beginning consists of four main nested loops:
- Loop 1 loops over the total key length (48) to guess each key character individually.
- Loop 2 loops over all padding characters. Base64 necessitates padding as its input must be in multiples of 4, and the exploit code examines each key character individually. For instance, when determining the second key character, two padding characters are required. Padding (if correct) also helps to focus on one key character at a time.This means it helps triggering an error for a single character.
- Loop 3 loops over the key character set, which consists of all possible characters for the key.
- Loop 4 loops over the accuracy threshold, which consists of all possible characters that could appear in the (base64-encoded) plaintext (i.e., 64 characters). Within this last loop, the plaintext is created for which it is checked if the (so-far-guessed) key works. The assumption is that if the key is correct, any plaintext that is encrypt on the hackers side should be decryptable on the server side.
If the plaintext does not work, a new key character is chosen through loop 3 for the same padding. Once the exploit has gone through all key characters, it will go through the same procedure in the next padding. With a throttling of one second, this could take up to 2.37 years or 48 (number of characters in key) * 256 (number of padding characters) * 95 (number of characters in key character set) * 64 (accuracy iterations) requests.
In reality, the worst case is slightly faster since finding a valid padding is more challenging with decreasing padding characters in each block. To locate the first key character of a block, the process requires 3 padding characters, whereas for determining the third key character, only 1 padding character is necessary. Therefore, there are different worst-case scenarios depending on the number of padding characters needed

Exploit 1 uses several optimization strategies. It focuses on reducing the possibility space by using padding and pre-defined character sets for the secret key. However, further optimization is needed to reuse information about working paddings from loop 2 for each new key character iteration.
Exploit 2: The Fully Optimized Exploit
SRLabs’ research approach, assuming a throttling of one second, resulted in a worst-case duration of 32 minutes. Unlike other exploits that confirm possible key characters, this approach sent probes to exclude sets of potential key characters. It involved offline determination of positive or negative error messages for each encrypted character and possible key character. The process had four steps:
- Step 1: Choose three encrypted characters that grouped the key character set into three groups (“buckets”)
- Step 2: Determine all possible combinations of these encrypted characters and sorted them by likelihood
- Step 3: Use the sorted combinations of encrypted characters, to figure out which bucket the 4 characters of a key block belonged to
- Step 4: performed divide-and-conquer for each key character
Simplified example
- Assume 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C,D, E, and F are the possible key characters
- 0, 1, 2, 3, 4, 5, 6, 8, and 9 result in a positive error message when XOR-ed with the encrypted byte ‘0x??’ (simplified example, no specific byte is provided)
- A, B, C, D, E, and F result in a negative error message
- If ‘0x??’ is send to the server and returns a bad result, the possible keys characters are A, B, C, D, E, and F
- In the next step an encrypted character is determined that returns a positive or negative result for half of the possible key characters
- Continue divide-and-conquer until there is only one possible character
Step 1
First the detector bytes are need, which divide the key characters into buckets. A detector byte of a bucket always leads to a valid base 64 character if XOR-ed with characters of this specific bucket. Table 2.1-4 show the results of XOR combinations of different example detector bytes and key characters. The green color indicates that the XOR result is a valid base 64 character (i.e., positive error message).
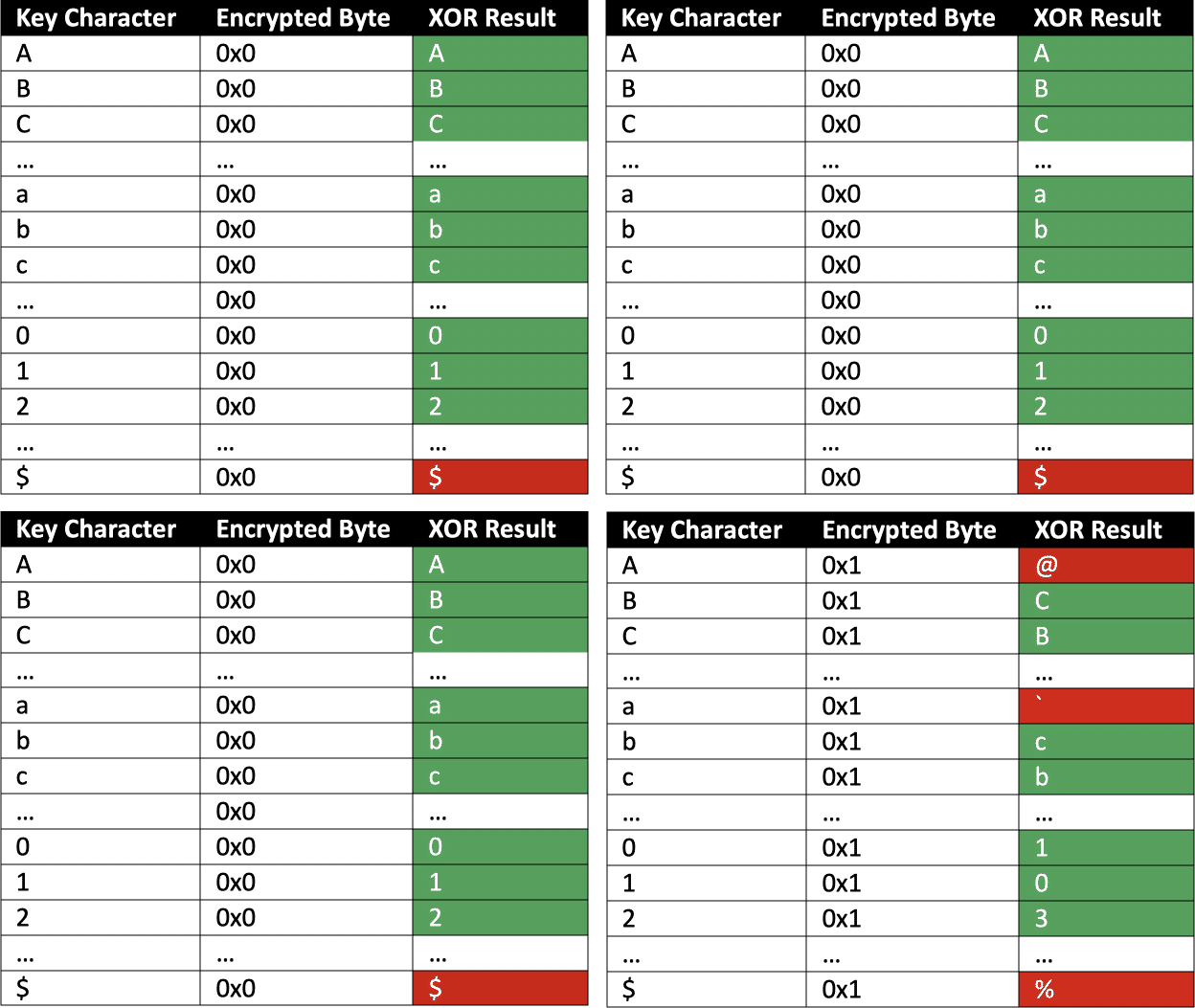
The first detector byte should cover a wide range of characters to quickly find a positive error message for divide-and-conquer. They determined three bytes for all 95 printable ASCII characters, dividing the key characters into 3 buckets (Table 3).

Please be aware that if a password includes the “=” sign, which is a valid base64 character, you can employ a specific technique or workaround. However, we will not discuss the details of this technique here.
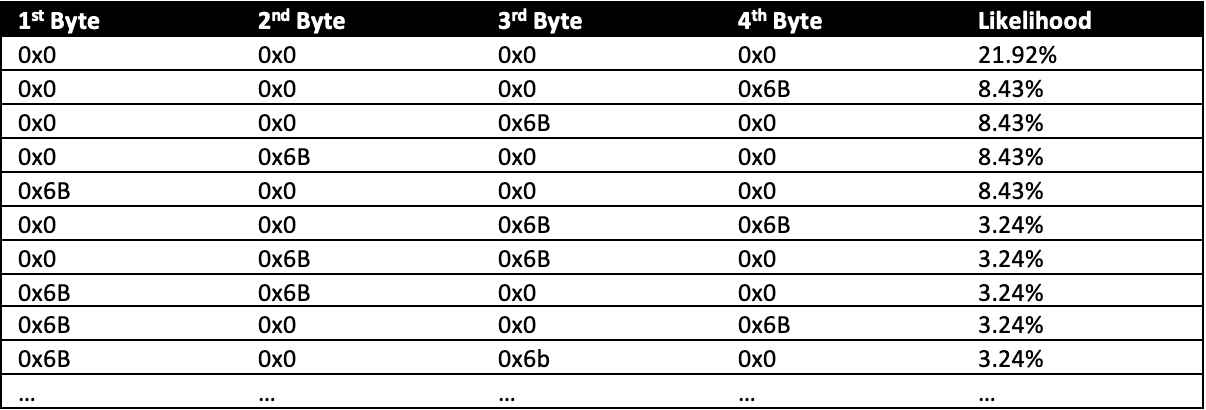
Step 2
In the next step, we need to determine all possible combinations of detector bytes. Ordering them by likelihood minimizes the number of requests needed to find out the first valid combination. It is essential to ensure that each position of the 4 characters is initially checked with the byte of the largest bucket (i.e., 0x0) and then sequentially with bytes of smaller buckets (i.e., 0x6B and 0x8). The reasoning for this is as follows: if 0x0 triggers a negative error message, it indicates that the potential key characters are present in the buckets associated with 0x6B or 0x8. If 0x6B yields negative error, sending 0x8 confirms printable ASCII character assumption.
Table 4 shows the ordered detector bytes by likelihood.
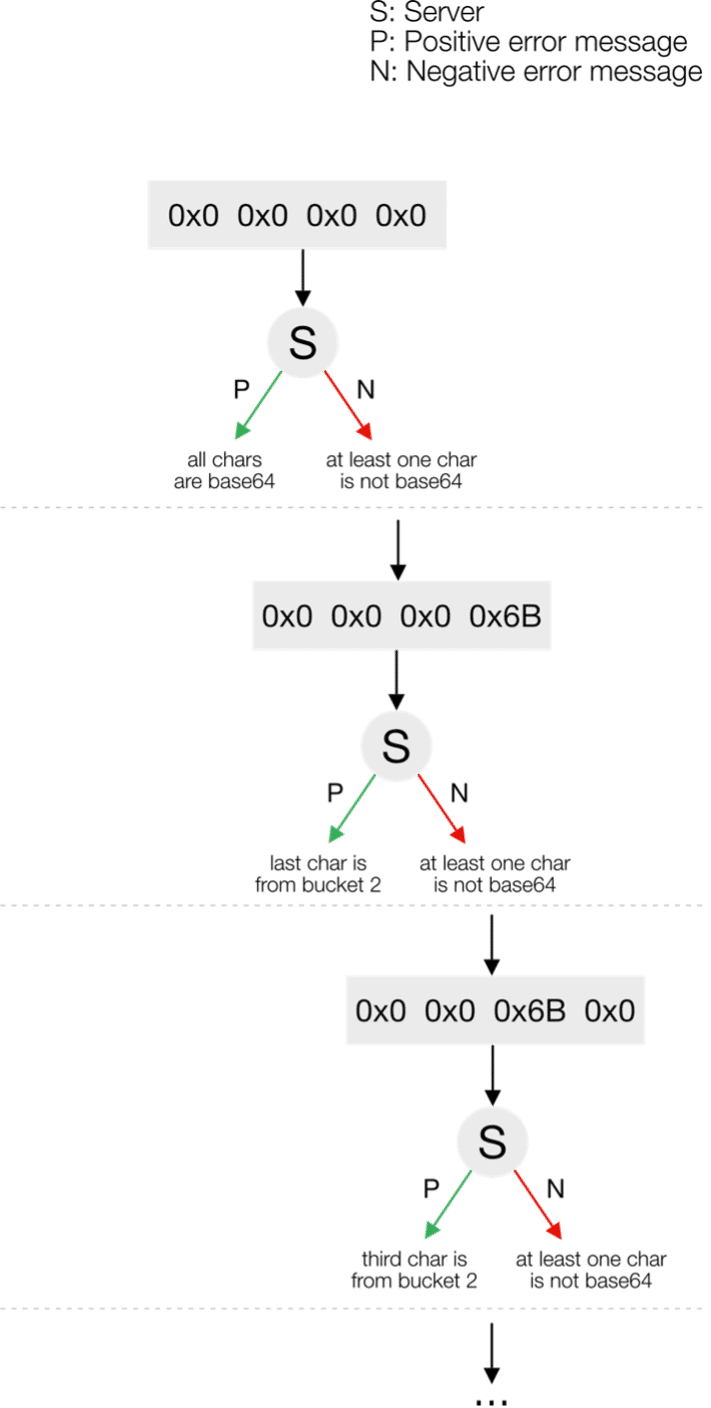
Step 3
In step 2, the team arranged and sent combinations of detector bytes to find valid buckets for the 4 disclosed characters. They referred to this process as a decision tree and represented it in Figure 7 since each server response influences the next request. For example, upon receiving a positive response in the third request (0x0 0x0 0x6B 0x0), they inferred that the first, second, and fourth characters pertain to the first bucket, which encompasses all base64 characters. The 3rd character belongs to the second bucket (seeFigure 7).
Step 4
Researchers had a valid detector byte combination for one key block (e.g., {0x6B, 0x0, 0x0, 0x0}). They identified a divide-and-conquer byte (0x6B) for the first detector byte. Half of the possible key characters return a positive error message, and the other half return a negative one.A positive error message indicates the first half, while a negative error message indicates the second half of the key character. This will again create a decision tree analogous to the detector byte decision tree (Figure 7). The process iterates until the key character is unmistakably identified. Then, the entire process repeats for the second detector byte (0x0) with a different bucket. In the worst-case scenario, it would take 32 minutes (throttling at one second) for the requests needed.
Key Takeaways
This research demonstrates how optimizing it can make the initially slow public exploit practical. The SRLabs researchers summarized some optimization strategies they applied, which developers can also use when developing other exploits:
- Understand the key concepts behind the problem and its implications: A very simple example is XOR. Understanding its functionality and the property of XOR with 0x0 are both crucial. This understanding allowed developing the concept around detector bytes in the first place.
-
Before the exploitation, consider how you can generate information actively: Begin by gathering as much information as possible and reducing noise. It is logical to explore potential simulations and how they can contribute additional information for exploitation. In this case, the team determined how the target server would respond to specific input and made use of the knowledge about the behavior. This worked without sending a single request to the target server.
- Think about how you can (re-)use information during the exploitation: Optimization involves using available information cleverly. This means that all helpful information in answers from previous requests should flow into ensuing requests. instead of guessing paddings for each iteration again and again as done in exploit 1, the researchers only determined it once in the form of a working detector byte combination. This allowed them to remove one factor from the complexity calculation.
- Reduce the problem to its essence: Unlike other exploits, they used encrypted strings as a starting point instead of encrypting plaintext characters. As a result, SRLabs was able to reduce the complexity of the problem.
- Decide on a suitable, algorithmic method: Broadly speaking, one can guess keys by either excluding possibilities or confirming them. Exploit 1 sought confirmation for a guessed key, while the optimized exploit excluded wrong options through divide-and-conquer. This requires fundamentals in data structures and algorithms.